
Il Natural Language Processing (NLP) consiste in un range di metodi e tecniche computazionali, con fondamenti teorici, per analizzare e rappresentare testi in linguaggio naturale ad uno o più livelli di analisi linguistica allo scopo di ottenere elaborazioni di linguaggio human-like per un range di task ed applicazioni.
Il Natural Language Processing (NLP) consiste in un range di metodi e tecniche computazionali, con fondamenti teorici, per analizzare e rappresentare testi in linguaggio naturale ad uno o più livelli di analisi linguistica allo scopo di ottenere elaborazioni di linguaggio human-like per un range di task ed applicazioni.
Il metodo più esplicativo per presentare ciò che in effetti avviene in un sistema di elaborazione di linguaggio naturale è tramite l’approccio dei “livelli di linguaggio”, detto anche modello sincronico e che si distingue dal modello sequenziale il quale ipotizza che i modelli di elaborazione seguono l’un l’altro in modalità strettamente sequenziale; tale modello, invece, risulta più dinamico poiché i livelli interagiscono tra di loro in vario ordine. Di frequente si utilizzano le informazioni, che si ricavano da ciò che è tipicamente inteso come livello superiore di elaborazione, per supporto nell’analisi di livello più basso. Per esempio, la conoscenza pragmatica che il documento che si sta leggendo riguarda la biologia sarà utilizzata quando si riscontra una specifica parola che ha più significati possibili, e la parola sarà interpretata come avente un significato che rientra nell’ambito della biologia. I livelli del Natural Language Processing sono:
- Fonologico: questo livello ha a che fare con l’interpretazione del suono della pronuncia delle parole e tra le parole. Ci sono, infatti, tre tipi di regole utilizzate nell’analisi fonologica: 1) regole di fonetica: per il suono delle parole; 2) regole fonemiche: per le variazioni di pronuncia quando le parole sono pronunciate assieme; 3) regole prosodiche: per l’oscillazione dell’accento tonico e dell’intonazione in una sentenza;
- Morfologico: questo livello ha a che fare con il fatto che le parole sono composte di morfemi, le più piccole unità di significato. Per esempio, la parola ‘preregistrazione’ può essere morfologicamente analizzata in tre morfemi distinti: il prefisso ‘pre’, la radice ‘registra’ ed il suffisso ‘zione’. Poiché il significato di ogni morfema rimane invariato nelle parole, una persona può suddividere la parola nei suoi morfemi costituenti al fine di comprendere il suo significato. Allo stesso modo, un sistema NLP può riconoscere il significato da ogni morfema in modo da ottenerne e rappresentarne il significato; per esempio, in inglese, aggiungendo il suffisso ‘ed’ adun verbo, si comunica che l’azione del verbo avviene nel passato. Questo è un pezzo chiave nel significato, ed infatti, di frequente si evince dal testo ciò dall’utilizzo del morfema ‘ed’;
- Lessicale: a questo livello, le persone, così come i sistemi NLP, interpretano il significato di parole singole. Vari tipi di elaborazione contribuiscono alla comprensione a livello della parola, la prima di queste è l’assegnamento di un singolo tag di parte del discorso ad ogni parola; in tale elaborazione, alle parole che possono fungere da più di una parte del discorso è assegnato il tag di parte del discorso più probabile in base al contesto in cui si trova la parola;
- Sintattico: questo livello si focalizza sull’analisi delle parole in una sentenza in modo da rivelare la struttura grammaticale della sentenza. Ciò richiede sia una grammatica sia un parser. L’output di questo livello di elaborazione è una rappresentazione della sentenza che evidenzia le relazioni di dipendenza strutturale tra le parole. La sintassi porta al significato in molti linguaggi poiché l’ordine e la dipendenza contribuiscono al significato;
- Semantico: questo è un livello al quale molte persone credono sia determinato il significato; comunque, come possiamo vedere nella definizione precedente di livelli, sono tutti i livelli a contribuire al significato. L’elaborazione semantica determina il possibile significato di una sentenza, concentrandosi sulle interazioni tra i significati delle parole nella sentenza. Questo livello di elaborazione può includere la disambiguazione semantica di parole con multipli significati; in modo analogo a come è realizzata la disambiguazione di parole che possono fungere da più parti del discorso a livello sintattico. Per esempio, tra i vari significati, ‘file’ come nome può intendere sia una cartella per memorizzare documenti o una linea di individui in una coda. Se è richiesta l’informazione dal resto della sentenza per la disambiguazione, il livello semantico, non lessicale, effettuerà la disambiguazione. Vari metodi possono essere implementati per realizzare la disambiguazione, alcuni dei quali richiedono informazioni sulla frequenza con la quale ogni senso si verifica in un particolare corpus di interesse, o alcuni dei quali richiedono la considerazione del contesto locale ed altri utilizzano la conoscenza pragmatica del dominio del documento;
- Discorso: mentre la sintassi e la semantica lavorano con unità di lunghezza pari ad una sentenza, tale livello lavora invece su testi più lunghi, ovvero non interpreta più sentenze di testi semplicemente come sentenze concatenate, ognuna delle quali può essere interpretata singolarmente; piuttosto, si concentra sulle proprietà del testo per intero che porta al significato facendo connessioni tra sentenze componenti. Vari tipi di elaborazione possono avvenire a questo livello, due dei più comuni sono la risoluzione di anafore ed il riconoscimento di struttura del testo/discorso. La risoluzione di anafore consiste nel sostituire le parole come i pronomi, che sono semanticamente poco rilevanti, con l’entità appropriata cui si riferiscono. Il riconoscimento della struttura del testo/discorso determina le funzioni delle sentenze nel testo, che, a turno, si aggiungono alla rappresentazione significativa del testo;
- Pragmatico: questo livello ha a che fare con l’utilizzo determinato del linguaggio in situazioni ed utilizza il contesto per la comprensione. Per esempio, le seguenti due sentenze richiedono la risoluzione del termine anaforico ‘they’ ma tale risoluzione richiede la comprensione pragmatica:
- “The city councilors refused the demonstrators a permit because they feared violence.”
- “The city councilors refused the demonstrators a permit because they advocated revolution.”
I sistemi NLP attuali tendono ad implementare moduli per realizzare principalmente i livelli più bassi di elaborazione, per vari motivi: prima di tutto l’applicazione può non richiedere l’interpretazione a livelli più alti; in secondo luogo, i livelli più bassi sono stati studiati ed implementati più accuratamente; in fine, i livelli più bassi hanno a che fare con unità di analisi più piccole, come morfemi, parole e sentenze, che sono governate da regole, a differenza dei livelli più alti di elaborazione del linguaggio, che invece hanno a che fare con testi e che sono solo governati da regolarità. Qualsiasi applicazione che utilizza testo è un candidato per essere un’applicazione di NLP; le applicazioni più frequenti che utilizzano NLP includono le seguenti:
- Information Retrieval: è l’insieme delle tecniche utilizzate per il recupero mirato dell’informazione in formato elettronico. Per “informazione” si intendono tutti i documenti, i metadati, i file presenti all’interno di banche dati o nel world wide web;
- Information Extraction: si focalizza sul riconoscimento, tagging ed estrazione in una rappresentazione strutturata di certi elementi di informazione chiave, come persone, locazioni, organizzazioni, da ampie collezioni di testo;
- Question-Answering: a differenza dell’Information Retrieval, che fornisce una lista di documenti potenzialmente rilevanti in risposta ad una query dell’utente, question-answering fornisce all’utente solo il testo della risposta o i passaggi che forniscono la risposta;
- Sintesi: i livelli più alti di NLP possono consentire un’implementazione che reduce un testo lungo in uno più breve, una rappresentazione narrativa abbreviata e significativo del documento originale;
- Dialogue Systems: attualmente utilizzano i livelli di linguaggio lessicale e fonetico, ma si ritiene che l’impiego di tutti i livelli sopra riportati offrano il potenziale per dialogue systems migliori.
Molte tecniche di Natural Language Processing, incluse lo stemming, il part-of-speech tagging, il riconoscimento di parole composte, decomposizione, word sense disambiguation e altre, sono utilizzate nell’Information Retrieval (IR). Molti altri task di IR utilizzano tecniche molto simili, come il clustering di documenti, il filtering, il rilevamento di link, ed esse possono essere combinate con NLP in maniera simile al document retrieval.
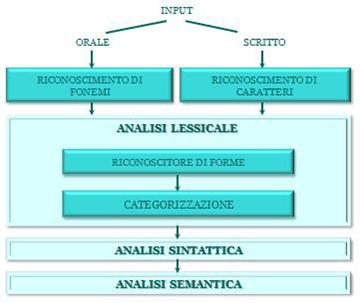
Un sistema per l’analisi di input linguistici ha un’architettura, rappresentata secondo uno schema a blocchi in Figura 2.1, e si compone dei seguenti elementi:
- Due sistemi di riconoscimento, l’input può essere sia una produzione scritta sia orale, ma i sistemi che operano l’analisi possono lavorare indistintamente su ognuno di essi, a condizione che siano in una rappresentazione macchina interna che il calcolatore è in grado di manipolare. Il sistema che opera il riconoscimento dei fonemi prende il nome di Speech‐to‐Text System, e sarà oggetto di un paragrafo nel capitolo delle tecnologie del parlato. Il sistema per la conversione dei grafemi in una rappresentazione macchina interna realizza uno scanning del documento cartaceo generando un file. Tale sistema è detto Optical Character Recognitioner (OCR). L’OCR può basare la sua azione su una base di conoscenza che contiene tutti i possibili elementi tipografici per ogni simbolo della lingua naturale. Tale approccio diventa impraticabile nel caso del riconoscimento della grafia, in tal caso si passa ad un particolare metodologia di Pattern Recognition, detta a riconoscimento strutturale. Si considerare una prospettiva gerarchica, dove gli elementi da riconoscere vengono visti come composti da componenti più semplici, detti primitivi. Il riconoscimento di un campione è dato da tipo di primitivi che lo costituiscono e dalla relazione di composizione intercorrente;
- Analisi lessicale: ha il compito di riconoscere gli elementi lessicali, e assegnarvi informazioni in merito alla loro categoria grammaticale, risolvendo le ambiguità. Si compone di due sottosistemi:
- Riconoscitore di forme: ha il compito di riconoscere le forme atomiche oggetto delle future elaborazioni. Si compone di un Tokenizer che compone la successione di caratteri in ingresso in unità linguistiche, ad esempio parole; e di uno Stemmer, che riconosce le possibili forme flesse di una unità linguistica e ne associa la forma radicale e le meta-informazioni di flessione;
- Categorizzazione, o Tagger: associa ad ogni unità linguistica una delle possibili classi morfologico‐sintattiche.
Gli ostacoli che si possono riscontrare in un’analisi lessicale sono vari. Nella Tokenizzazione, il problema è dato dalla non determinatezza dei delimitatori: essi dipendono fortemente dalla lingua adoperata nel testo e sono presenti irregolarità (unità atomiche composte da un insieme di parole, i.e Polirematiche). Inoltre, è possibile che un carattere di delimitazione non sia adoperato per delimitare parole (ad esempio il punto nelle sigle). Per lo stemmer è possibile che una forma flessa possa appartenere a varie possibili forme radicali. Nella classificazione, non è univoca l’appartenenza di una unità linguistica ad una classe morfologico-sintattica. I due sottosistemi sono rappresentati in figura collegati in serie, ma spesso è necessario un loro lavoro sinergico, dal momento che l’uno può aiutare a risolvere le ambiguità che ostacolano il lavoro dell’altro. Ad esempio l’ambiguità nell’appartenenza ad una forma flessa è risolvibile conoscendo la classificazione morfologica dell’unità. Ad esempio “porta” può essere sia la flessione del lemma sostantivo “porta”, che di quello verbale “portare”. Senza ulteriori informazioni il processo di disambiguazione sarebbe impossibile, ma con la conoscenza dell’appartenenza dell’unità al predicato verbale, è semplice operare l’associazione al lemma “portare”;
- Analisi sintattica, o Parser: ha il compito di assegnare una caratterizzazione sintattica alla frase. Dato in ingresso una frase ed una grammatica, il compito del parser è determinare se la frase può essere generata dalla grammatica e, in caso affermativo, assegnare alla frase un’adeguata rappresentazione, detto albero di parsing. Un albero di parsing è un grafo aciclico etichettato, caratterizzato da: un nodo radice, detto Sentence (S), dei nodi foglia con le parole della frase e dei nodi intermedi, che rappresentano la struttura sintattica assegnata alla frase;
- Analisi semantica: ha il compito di eseguire un’analisi semantica del testo in ingresso, generando meaning rapresentations. Si assegna a pezzi di struttura pezzi di significato. La struttura è composta da simboli e relazioni tra simboli che rappresentano stati del mondo.
Stopwords Removal
È un processo di trasformazione che elimina dai dati e dall’interrogazione le parole che non hanno un contenuto semantico utile. Solitamente sono eliminate le congiunzioni, gli articoli e le parole molto frequenti:
- Le parole da eliminare sono scelte a priori da un esperto;
- Le parole da eliminare dipendono dalla lingua utilizzata.
L’eliminazione delle stopword serve ad evitare che due frasi o documenti risultino simili perché contengono le stesse congiunzioni e gli stessi articoli. Eliminando le stopword si da maggior peso alle altre parole che, solitamente, hanno un maggiore significato semantico. Ci sono però molti contro-esempi che mostrano come l’eliminazione delle stop word sia inefficace e controproducente, ad esempio: 1. To be or not to be 2. New Year celebrations 3. Will and Grace 4. On the road again (Le parole in corsivo sono considerate stopwords) Adattare la lista delle stopword al dominio in esame può portare ad un miglioramento significativo dei risultati.
Stemming
Gli stemmer sono analizzatori morfologici, che associano alle forme flesse di un termine, la sua forma radicale. La forma radicale può essere pensata come il lemma che si trova normalmente sui dizionari. I due metodi principali sono:
- il linguistic/dictionary-based stemming;
- il Porter-style stemming.
Il linguistic/dictionary-based stemming ha un’accuratezza di stemming più elevata, ma anche costi di implementazione e di elaborazione più elevati ed una copertura più bassa. Il Porter-style stemming ha un’accuratezza minore, ma costi di implementazione e di elaborazione più bassi ed è solitamente sufficiente per l’IR. Lo stemming mappa vari termini ad una forma base, la quale è poi utilizzata come termine nel modello a spazio vettoriale. Ciò vuol dire che, nella media, aumenta le similarità tra documenti o documenti e query poiché avranno più termini comuni in seguito allo stemming, ma non prima. Lo stemming ha un costo di elaborazione relativamente basso, specialmente quando si utilizza il Porter-style stemming, il quale riduce la dimensione dell’indice e solitamente migliora di poco i risultati, secondo [Strzalkowski]: 0.328 la precisione media senza stemming, 0.356 con lo stemming. Ciò lo rende molto appetito per l’utilizzo nell’IR. Il vantaggio dello stemming che si è ritrovato tramite molte ricerche risulta in una sovrapposizione di casi positivi e negativi. L’inflexional stemming è per lo più vantaggioso, anche se vi sono casi ambigui nei quali lo stemming risulta contestabile. Per esempio, un utente probabilmente non sta cercando la parola ‘window’ quando il termine della sua query è ‘Windows’ (parte della casa vs. il sistema operativo). Il derivational stemming ha effetti misti: è più adatto a mappare la parola ‘resignation’ con la parola ‘resign’, e ‘assassination’ con ‘assassin’. Ma molti mapping generati da un semplice stemmer sono errati o introducono ambiguità: ‘expedition’ è diverso da ‘expedite’; ‘importance’ è diverso da ‘import’; etc. Come alternativa non-NLP allo stemming potrebbe essere usato il character n-grams, che consente un’elaborazione di documenti più semplice e indipendente dal linguaggio, ma a costo di una maggiore dimensione dell’indice. Complessivamente, comunque, i risultati dello stemming risultano confrontabili con quelli ottenuti utilizzando il character n-grams, e lo stemming risulta quindi preferito in quanto richiede meno memoria.
Part-of-Speech Tagging
Il Part-of-Speech Tagging ha il compito di assegnare una categoria sintattica ad ogni parola in un testo, risolvendo per cui alcune ambiguità, come visto prima. Le parole appartenenti ad una lingua naturale possono essere classificati in base ad un insieme di classi morfologiche, che costituiscono un insieme che prende il nome di Tagset di Tagging. Le parti del discorso possono essere categorizzate come classi chiuse, ovvero quelle in cui la condizione di appartenenza è relativamente fissa, ad esempio le proposizioni, e classi aperte, in cui è possibile di volta in volta trovare nuovi elementi, dovute a parole di recente conio. Nei sistemi di elaborazione del linguaggio naturale esiste una fase chiamata Part-Of-Speech tagging o POS-tagging (in italiano la traduzione sarebbe “etichettatura delle parti del discorso”). In questa fase si etichettano le parole individuate nella fase di analisi lessicale con il POS corrispondente, senza eseguire una vera e propria analisi sintattica, ma ricorrendo in genere ad informazioni statistiche (ad esempio, il TnT tagger, basato su trigrammi) o a regole. Le etichette, o tags, sono reperite attraverso tagset, mappe da categorie lessicali in tags, che oltre a contenere i tag per le otto categorie lessicali di base, includono delle specializzazioni o raffinamenti, che distinguono delle sottocategorie, spesso in base al significato della parola. Nella tabella sottostante è riportato un estratto dal tagset di esempio, che rappresenta il primo corpus etichettato sintatticamente. Un esempio di POS-tagging è il seguente: data la frase book that flight (prenota quel volo), le etichettature possibili, considerando il tagset del Penn Treebank corpus, sono: book:NN that:WDT ight:NN oppure book:VB that:WDT ight:NN, per via dell’ambiguità della parola book. In questo caso l’etichettatura corretta è quella che assegna a book il tag VB.
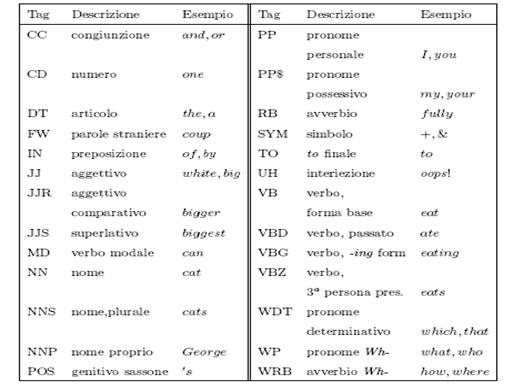
Gli algoritmi di tagging ricadono in tre gruppi differenti:
- Rule‐based tagger, generalmente posseggono un grande database di regole di determinazione della parte del discorso di una unità linguistica, ad esempio una unità che segue un articolo è un nome.
Un esempio è il tagger ENGTWOL, un analizzatore morfologico a due livelli:
- Per primo viene consultato un dizionario dei termini, con la parte radicale delle unità linguistiche, il POS tag e alcune informazioni aggiuntive, e a tutte le unità della frase da analizzare vengono associate una o più etichette sulla base delle entry del dizionario;
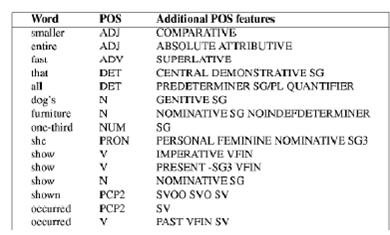
- Un insieme di regole sono applicate per risolvere le ambiguità morfologiche, ovvero unità che presentano più di una etichetta.

- Stochastic tagger, adoperano un corpus per determinare la probabilità che una data unità linguistica abbia un preciso tag morfologico in un preciso contesto:
minimizza {P(unità | tag) * P(tag | precedenti n tag)}.
Un esempio di POS-tagger statistico è il tagger basato su bigrammi: data una parola ambigua wi con un insieme J di possibili tag, il tagger seleziona come tag quello più probabile considerando il tag precedente ti-1
ti=arg max j in J P (tj | ti-1, wi)
La precisione dei migliori pos-tagger statistici si aggira intorno al 95%, cosa che ha permesso, in alcune applicazioni, lo snellimento della fase di analisi sintattica, se non addirittura l’eliminazione della fase stessa (ad esempio, per determinare se un documento parla di sport o di economia, può essere sufficiente considerare solamente i nomi che compaiono nel documento, senza il bisogno di analizzare sintatticamente le frasi che lo compongono).
- Trasformation‐based tagger, è un approccio ibrido, e come gli algoritmi rule‐based ha un insieme di regole per l’assegnazione dei tag alle unità linguistiche, ma ha anche una componente statistica: le regole non sono inserite da un esperto, ma computate a partire da un corpus appositamente annotato. Un esempio è il Brill tagger, che opera seguendo questi passi:
- Ad ogni unità linguistica si applica il tag più probabile, con tale probabilità costruita a partire da un corpus di training annotato considerando solo le singole unità linguistiche;
- Successivamente si applicano delle regole di trasformazione, apprese dall’osservazione del training e considerando il cotesto all’interno di una frase, per correggere i tag erroneamente assegnati alle unità.
Per poter effettuare la lemmatizzazione e la lemmatizzazione semantica è necessario fare ricorso ad alcune risorse utilizzate nel campo dell’elaborazione del linguaggio naturale. In particolare, il Part-Of-Speech tagger permette di stabilire la categoria delle parole in modo da rendere possibile la ricerca della parola in un apposito tesauro, per estrarre i sinonimi, o in una ontologia, per estrarre una rappresentazione semantica della parola e le sue relazioni con altri concetti. Queste relazioni, infine, vengono utilizzate sia per effettuare alcuni tipi di elaborazioni sul testo come l’espansione delle query, sia nell’ambito di sistemi di disambiguazione non supervisionati, come il disambiguatore semantico basato su densità concettuale.
Parser
Un processo di parsing può essere visto con un algoritmo di ricerca del corretto albero sintattico per una data frase, all’interno dello spazio di tutti i possibili alberi sintattici generabili a partire delle regole di una grammatica. I parametri che vanno dati al processo di definizione dell’albero sono:
- le regole grammaticali, che predicono come da un nodo radice S ci siano solo alcune vie di scomposizione possibili per ottenere i nodi terminali;
- le parole della frase, che ricordano come la (s)composizione di S debba terminare.
I due principali approcci al parsing sono:
- Top‐down o goal‐driven approach, cerca il corretto albero applicando le regole grammaticali a partire dal nodo radice S, provando a raggiungere i nodi foglia;
- Bottom‐up o data‐driven approach, si inizia con le parole che compongono la frase di input, da cui si inizia ad applicare le regole grammaticali fino a poter arrivare al nodo radice S.
La strategia top‐down non perde tempo esplorando alberi che non portino a S come nodo radice, cosa che invece si verifica con la strategia bottom.up. Il top‐down, però, genera un grande insieme di alberi S‐rooted che sono inconsistenti con l’ingresso fornito, dal momento che gli alberi sono generati senza esaminare l’input linguistico. Bottom‐up non produce mai alberi inconsistenti con l’input linguistico. Quando in un nodo dell’albero sintattico si applicano delle regole grammaticali, si possono generare un insieme di percorsi alternativi verso uno o più nodi. Tale ramificazione non è espandibile in parallelo, ma va considerato un percorso per volta. Per questo l’esplorazione è fatta secondo due distinte strategie:
- Depth‐first, la ricerca procede espandendo sempre il primo nodo generato, e operando un backtracking nel caso il percorso non fosse giusto;
- Breadth‐first, la ricerca procede espandendo prima tutti nodi di un livello, per poi scendere al livello successivo.
Ci sono molti modi di combinare previsioni top‐down con dati bottom‐up per ottenere ricerche più efficienti. La maggior parte usano un tipo come meccanismo di controllo per la generazione degli alberi, e l’altro come filtro per scartare a priori alberi che certamente non sono corretti, un esempio è l’algoritmo del Left Corner. L’idea alla base di quest’algoritmo è di combinare una strategia di generazione degli alberi di tipo Top‐down, con il filtraggio con considerazioni di natura Bottom‐up.
L’algoritmo si memorizza la prima parola dell’input (left corner), e non si devono considerare le regole grammaticali in cui sul ramo sinistro della derivazione si ha incongruenza con il left corner. Questi approcci di parsing, soprattutto se si considera una strategia del tipo Depth‐first, possono incorrere in situazioni di stallo, senza mai giungere ad un risultato. Ciò si verifica quando la grammatica in ingresso al parser è di tipo left‐recursive. Una grammatica si dice ricorsiva a sinistra,, se ammette una regola del tipo A →*Aα (ad esempio, NP→ NP PP), ovvero se contiene un simbolo non terminale che è sia parte della condizione di innesco che prodotto di una regola grammaticale. Esistono due modi per poter ovviare a questo inconveniente:
- riformulare le regole che presentano ricorsione a sinistra, ottenendo così quella che prende il nome di weakly equivalent grammar;
- gestire esplicitamente il processo di esplorazione, evitando situazioni di stallo.
Nell’ottica del secondo approccio si inserisce la programmazione dinamica, una metodologia di parsing in cui si memorizzano i risultati intermedi con l’intento di non ripetere il lavoro già fatto che si può evitare e non cadere nella ricorsione a sinistra. I risultati intermedi vengono memorizzati in una struttura che prende il nome di chart. Un chart è un grafo aciclico etichettato, dove un arco contiene l’indicazione dei nodi iniziali e terminali e della regola che deve venir applicata.
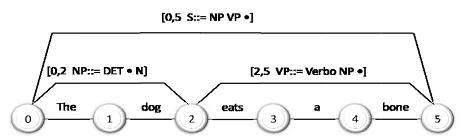
L’algoritmo di Earley è un esempio di programmazione dinamica che opera su un chart per realizzare un task di parsing. L’algoritmo inizia con una fase di inizializzazione applicando la regola γ → S. Ad ogni passo dell’algoritmo, uno dei seguenti tre operatori viene applicato ad ogni nodo del chart, in funzione del suo stato:
- Previsione (Predictor): crea nuovi stati nell’entrata corrente del chart, rappresentando le aspettative top‐down della grammatica; verrà quindi creato un numero di stati uguale alle possibilità di espansione di ogni nodo non terminale nella grammatica;
- Scansione (Scanner): verifica se nell’input esiste, nella posizione adeguata, una parola la cui categoria combacia con quella prevista dallo stato a cui la regola si trova. Se il confronto è positivo, la scansione produce un nuovo stato in cui l’indice di posizione viene spostato dopo la parola riconosciuta. Tale stato verrà aggiunto all’entrata successiva del chart;
- Completamento (Completer): quando l’indicatore di posizione raggiunge l’estrema destra della regola, questa procedura riconosce che un sintagma significativo è stato riconosciuto e verifica se l’avvenuto riconoscimento è utile per completare qualche altra regola rimasta in attesa di quella categoria.
Una volta costruito il chart, è possibile ottenere un albero di parsing, estraendo l’arco o l’insieme di archi che dal primo nodo portano all’ultimo. Anche per il parsing esistono degli approcci statistici, dove si scelgono le regole da espandere in base a probabilità calcolate a partire da un corpus, per arrivare il prima possibile ad un’analisi e restituirla come “più probabile”. Dato un insieme di regole, fornite sia da esperti che definite a partire da un analisi empirica di un insieme di testi, si definisce la probabilità di applicazione della regola come: vale a dire, la probabilità, nota la parte di innesto, è pari al numero di volte in cui la regola è applicata nel corpus, diviso il numero di occorrenze della parte di innesco.
Word Sense Disambiguation
La Word Sense Disambiguation ha il compito di distinguere il corretto senso di una parola in un contesto. Quando è utilizzata nell’IR, i termini sono rimpiazzati da i loro significati nel vettore del documento. Un fattore negativo nell’utilizzo di un’ontologia general-purpose è che la word sense disambiguation per query brevi risulta difficile a causa della mancanza di contesto, mentre risulta non necessaria per query lunghe in quanto gli altri termini contribuiscono comunque a restringere la ricerca.
COMMENTS