
In questo articolo vedremo come utilizzare la libreria Java Apache PDFBox per manipolare documenti in formato PDF. PDFBox è una libreria Java rilasciata con licenza Open Source (Apache License v2.0), la quale permette di creare un nuovo documento PDF, manipolare documenti esistenti ed estrarre il contenuto da questi documenti. E' possibile inoltre scaricarne una versione stand-alone (cioè che funziona senza dover sviluppare codice che la utilizzi), che permette di effettuare una serie di operazioni agendo direttamente da linea di comando.
In questo articolo vedremo come utilizzare la libreria Java Apache PDFBox per manipolare documenti in formato PDF. PDFBox è una libreria Java rilasciata con licenza Open Source (Apache License v2.0), la quale permette di creare un nuovo documento PDF, manipolare documenti esistenti ed estrarre il contenuto da questi documenti.
E’ possibile inoltre scaricarne una versione stand-alone (cioè che funziona senza dover sviluppare codice che la utilizzi), che permette di effettuare una serie di operazioni agendo direttamente da linea di comando.
Vediamo ora come è strutturato Apache PDFBox, dopo di che faremo degli esempi pratici in Java.
I documenti PDF sono degli stream di oggetti di tipo base, questi oggetti di basso livello sono rappresentati in PDFBox nel package org.apache.pdfbox.cos package. Gli oggetti base in PDF sono:
| PDF Type | Descrizione | Esempio | Classi PDFBox |
|---|---|---|---|
| Array | Una lista ordinata di elementi | [1 2 3] | org.apache.pdfbox .cos.COSArray |
| Boolean | I valori True/False | true | org.apache.pdfbox .cos.COSBoolean |
| Dictionary | Una mappa di coppie chiave/valore | << /Type /XObject /Name (Name) /Size 1 >> | org.apache.pdfbox .cos.COSDictionary |
| Number | Numeri Interi e in virgola mobile | 1 2.3 | org.apache.pdfbox .cos.COSFloat .cos.COSInteger |
| Name | Un valore predefinito in un documento PDF, usato tipicamente come chiave in un dizionario | /Type | org.apache.pdfbox .cos.COSName |
| Object | Un Wrapper per ogni altrotipo di oggetto, il quale può essere utilizzato per referenziare un oggetto per più volte. Un oggetto è referenziato utilizzando due numeri: un number object e un generation number. All’inizio il generation number è 0 fino a che l’oggetto non venga rimpiazzato più tardi nello stream. | 12 0 obj << /Type /XObject >> endobj | org.apache.pdfbox .cos.COSObject |
| Stream | Uno stream di dati il più delle volte compresso. Questo viene usato per il contenuto della pagina, le immagini e per i font. | 12 0 obj << /Type /XObject >> stream 030004040404040404 endstream | org.apache.pdfbox .cos.COSStream |
| String | Una sequenza di caratteri. | (This is a string) | org.apache.pdfbox .cos.COSString |
Il modello basato su oggetti COS permette di accedere a qualsiasi elemento del documento PDF, ma per accedervi l’utente deve conoscere il nome dei parametri che vuole usare e ciò porta ad inevitabili errori. Di conseguenza è stato creato un altro Modello (PD Model) che offre delle agevolazioni per il programmatore. Ogni oggetto del documento ha un set di attributi definiti che possono essere disponibili nel dizionario. La libreria fornisce una classe PD Model per ogni tipo di oggetto del documento le quali forniscono dei metodi fortemente tipizzati che permetto di accedere agli attributi definiti. Di conseguenza il PD Model è collocabile al di sopra del COS Model come mostrato in figura:

Ovviamente nei nostri esempi faremo sempre uso delle classi del PD Model.
A questo punto scarichiamo la libreria all’indirizzo:
http://pdfbox.apache.org/download.html
scegliendo il file .jar pdfbox-version.jar (la 1.5.0 nel momento in cui scriviamo), dobbiamo inoltre scaricare sempre dalla stessa pagina il file di dipendenza .jsr fontbox-version.jar (è un componente stand-alone che permette di manipolare i formati dei font).
Una ulteriore dipendenza da soddisfare è la libreria commons-logging che possiamo scaricare da questa url:
http://apache.panu.it//commons/logging/binaries/commons-logging-1.1.1-bin.zip
Utilizzeremo per i nostri esempi Java l’IDE Eclipse.
Creiamo un nuovo Progetto Java in Eclipse (File -> New -> Java Project), creiamo una cartella lib e vi copiamo le libreria pdfbox-1.5.0.jar, fontbox-1.5.0.jar e commons-logging-1.1.1.jar, per cui avremo il nostro progetto così strutturato:
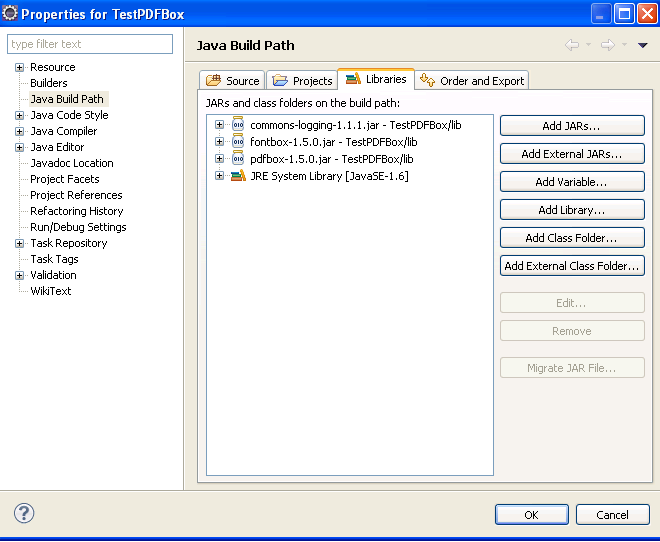
Dobbiamo poi includerle nel Build Path del nostro progetto: click col tasto destro sul progetto -> Build Path -> Configure Build Path):
- pdfbox-1.5.0.jar;
- fontbox-1.5.0.jar;
- commons-logging-1.1.1.jar.
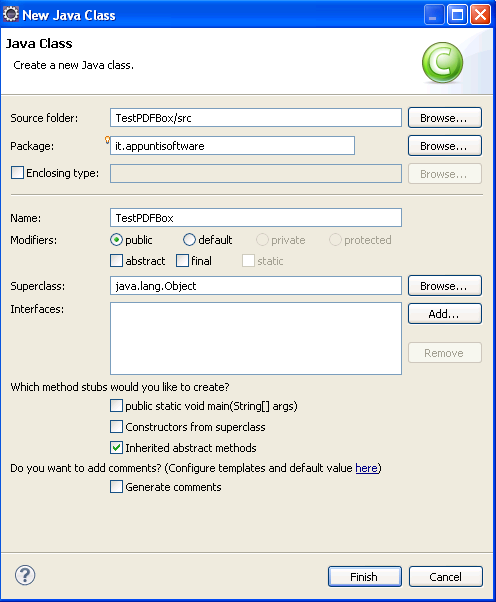
Creiamo ora una classe Java per poter provare la libreria (tasto destro sulla cartella src -> New -> Class), ed indichiamo il nome, il package e la JVM da utilizzare come riportato in figura:
Aggiungiamo del codice per creare una pagina PDF con un testo in una certa posizione della pagina:
package it.appuntisoftware;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.edit.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
public class test {
public static void main(String[] args) throws Exception{
PDDocument doc = null;
try{
doc = new PDDocument();
PDPage page = new PDPage();
doc.addPage( page );
PDPageContentStream contentStream = new PDPageContentStream(doc,
page);
PDFont font = PDType1Font.HELVETICA_BOLD;
contentStream.beginText();
contentStream.setFont( font, 12 );
contentStream.moveTextPositionByAmount( 100, 700 );
contentStream.drawString("Ciao da
AppuntiSoftware.it");
contentStream.endText();
contentStream.close();
doc.save("output.pdf");
doc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Con il codice precedente viene creato un file pdf dal nome output.pdf che viene salvato nella directory root del nostro progetto, all’interno del quale viene scritta la Stringa che abbiamo passato all’oggetto PDPageContentStream. Come vediamo la prima cosa da fare è creare un documento PDF (istanza di PDDocument) e poi aggiungervi una pagina (istanza di PDPage) con il metodo addPage().
A questo punto istanziamo uno stream a cui passiamo come argomento il documento e la pagina su cui agire. Abbiamo inoltre settato un font (Helvetica_Bold) col metodo setFont (prima lo abbiamo definito utilizzando un campo statico della classe PDType1Font). Con il metodo moveTextPositionByAmount( x , y) posizioniamo il cursore da cui iniziare a scrivere, è importante notare che nei documenti PDF la posizione (0 , 0 ) rappresenta l’angolo in basso a sinistra. Dopo aver chiuso lo stream possiamo procedere al salvataggio con il metodo save(nomefile).
Scriviamo un’altra classe in cui andiamo ad aprire un file pdf già esistente, lo modifichiamo e lo scriviamo su di un altro file:
package it.appuntisoftware;
import java.io.IOException;
import org.apache.pdfbox.exceptions.COSVisitorException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.edit.PDPageContentStream;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
public class TestPDFBox {
public static void main(String[] args){
PDDocument doc = null;
try{
doc = PDDocument.load("output.pdf" );
PDPage page = (PDPage)doc.getDocumentCatalog().getAllPages().get(0);
PDPageContentStream contentStream = new PDPageContentStream(doc, page,
true, true);
PDFont font = PDType1Font.HELVETICA_BOLD;
contentStream.beginText();
contentStream.setFont( font, 12 );
contentStream.moveTextPositionByAmount( 260, 700 );
contentStream.drawString( "!!!!!" );
contentStream.endText();
contentStream.close();
doc.save("outputMod.pdf");
doc.close();
} catch (IOException e) {
e.printStackTrace();
} catch (COSVisitorException e) {
e.printStackTrace();
}
}
}
Le differenze con il precedente esempio sono l’utilizzo di PDDocument.load(nomefile) con il quale carichiamo in memoria il file e con doc.getDocumentCatalog().getAllPages().get(indexpagina) recuperiamo la lista di tutte le pagine e ci posizioniamo sulla prima.
COMMENTS